Cloud Tasks + Firestore: The Durable Queue Pattern Most Tutorials Miss
Cloud Tasks alone is not a durable queue. Pair it with Firestore as the source of truth and you get rate control, retry, visibility, and real durability on Cloud Run.

A background discovery worker in one of our pipelines had been running for months. One Tuesday, a user pinged me: “records haven’t updated in two days.” I looked at the Firestore dashboard. The last_processed_id pointer was frozen at 18,836. It had been frozen for 30 hours.
I checked Cloud Run logs. No panic, no error, no crash. Just silence where progress used to be. The polling goroutine that advanced that pointer had died sixteen times in the previous 24 hours. Nobody noticed because each death looked like a graceful shutdown, not a failure.
The fix did not involve tuning memory, adding retries, or catching a missed error. The fix was realizing that the goroutine had no business existing in the first place.
Three Ways Your Cloud Run Goroutine Dies
You write Cloud Run services in Go. For long-running work, you reach for the natural tool:
func handleStart(w http.ResponseWriter, r *http.Request) {
go func() {
for {
processNextBatch()
time.Sleep(30 * time.Second)
}
}()
w.WriteHeader(202)
}This works on your laptop. It works in staging. It works in production for weeks. Then one day it silently stops. There are three reasons, and all three look identical from the outside.
OOM kill. Your container hit its memory limit. The Linux OOM killer reaped the process. Cloud Run logs a single line Instance terminated because memory limit of 512 MiB was exceeded and spins up a fresh instance to serve the next request. Your goroutine’s state, the in-flight HTTP connection, the half-written parse buffer, all of it, gone.
Idle reclaim. Your goroutine was doing real work, but no HTTP request came in for fifteen minutes. Cloud Run’s scale-to-zero logic tore down the instance. The platform has no idea your goroutine was busy. There is no signal, no grace period, just a SIGKILL nine seconds after SIGTERM if the process does not exit cleanly.
Deploy revision swap. You pushed a new revision. Cloud Run routes 100% of traffic to the new revision and drains the old one. Your goroutine on the old instance gets SIGTERM. You did not wire a signal handler. Nine seconds later, SIGKILL.
Each death leaves no error log, no panic trace, no stack dump. The goroutine was never the unit Cloud Run tracked. It was a passenger on a container that died for reasons unrelated to what the goroutine was doing.
The Patch Reflex
The first instinct is to make goroutines tougher. Trap SIGTERM, write progress to disk, take a heartbeat lease in Firestore so a reconcile job can reclaim a dropped lock. All of this works. All of it leaves residual tail risk.
A SIGTERM handler helps you finish the current item, not the next thousand. A heartbeat lease handles the goroutine that died, not the goroutine that was never going to be scheduled again. You are building a shock absorber on a chassis that wants to be in pieces.
The real question is: why is any long-lived mutable state sitting in RAM on a stateless container platform?
The Trap: “Just Use Cloud Tasks”
The usual advice here is Cloud Tasks. Tutorials show you:
// Enqueue work
task := &cloudtaskspb.Task{
MessageType: &cloudtaskspb.Task_HttpRequest{
HttpRequest: &cloudtaskspb.HttpRequest{
HttpMethod: cloudtaskspb.HttpMethod_POST,
Url: "https://my-service.run.app/process",
Body: payload,
},
},
}
client.CreateTask(ctx, &cloudtaskspb.CreateTaskRequest{
Parent: queuePath,
Task: task,
})Cloud Tasks has durable storage, automatic retries with exponential backoff, and rate limiting baked in. The tutorial ends there. Problem solved.
For toy workloads, that is fine. For anything real, it is subtly wrong in five ways that you only discover at 3am.
Tasks expire after 30 days. Cloud Tasks silently drops any task older than 30 days. If a batch fills your queue faster than it drains, the oldest tasks vanish with no alert. Your durable queue is durable only within a rolling month.
You cannot ask it business questions. “How many pending items are in the queue for partition A?” “What is the oldest pending item in partition B?” “Show me every item stuck in the ‘fetching-details’ stage.” Cloud Tasks has a task count and not much else. Your admin dashboard cannot query it the way you need.
Retry amplification compounds. A poison message that always fails gets retried up to your max_attempts. A poison batch of 10,000 such messages triples your queue depth for hours. Without a dead letter queue wired to an alert, you do not know it is happening.
Big payloads break schema migration. Tutorials tempt you to pack the work into the task body. A week later you add a field to your schema. Every already-queued task has the old shape, and the handler has to support both forever.
One misconfigured queue and you cannot reconstruct. If you fat-finger a queue config and tasks fail en masse, there is no upstream to replay from. Cloud Tasks was the upstream.
Cloud Tasks is a superb piece of infrastructure. It is not a database. Using it as one is the mistake.
The Correct Pattern
Firestore holds WHAT to do. Cloud Tasks controls WHEN and HOW FAST. They are two layers, not one.
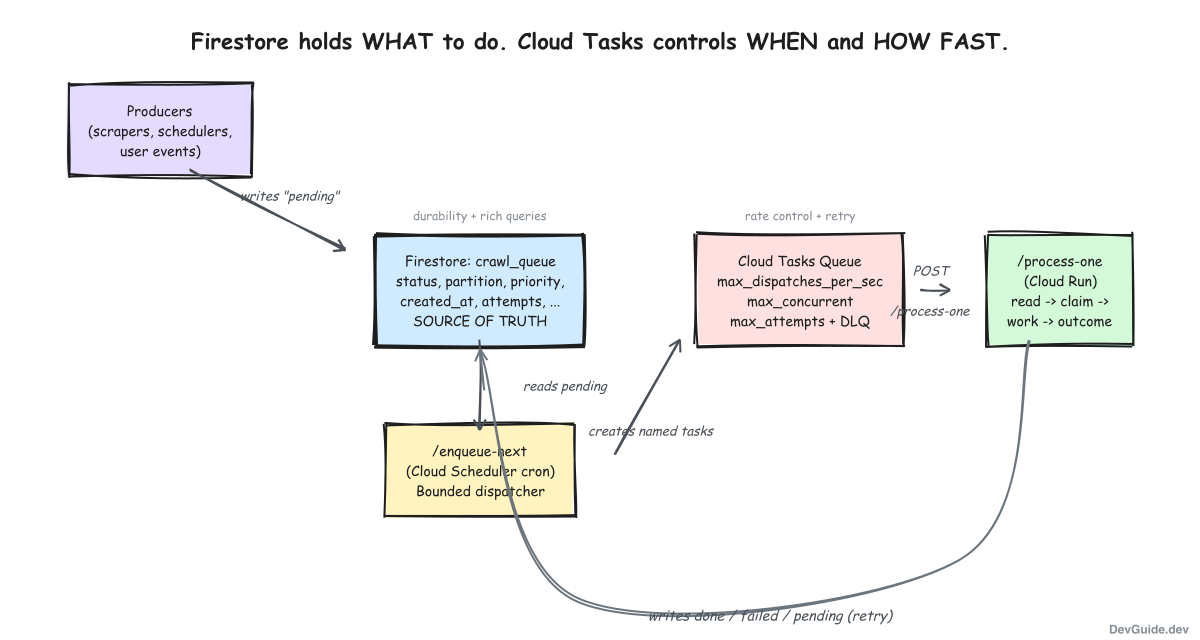
Three Cloud Run handlers, each with a single responsibility:
| Handler | Role |
|---|---|
| Producers | Whatever creates work. Write a pending doc to Firestore. That is it. |
| /enqueue-next | Periodic dispatcher. Read pending docs, create Cloud Tasks. |
| /process-one | Per-item handler. Invoked by Cloud Tasks with a single doc ID. |
The producers never talk to Cloud Tasks. The dispatcher never does work. The worker never touches the queue directly. Each layer fails independently and is independently observable.
The Firestore Work Queue
Minimum schema for a partitioned work queue:
work_queue/{doc_id}:
status: "pending" | "processing" | "done" | "failed"
partition: "a" | "b" | "c" # or whatever splits your domain
priority: int # lower = higher priority
created_at: timestamp
updated_at: timestamp
attempts: int
last_error: string
metadata: mapTwo indexes carry the weight. The composite (status, partition, priority, created_at) feeds the dispatcher. A simple index on updated_at powers the stuck-detection query that finds items lost mid-processing.
The doc ID should be a deterministic function of the work item: a record number, a URL hash, a combination that is unique and stable. Making the doc ID deterministic is what makes the producer idempotent. Writing the same pending doc twice is a no-op.
The /enqueue-next Handler
A Cloud Scheduler cron hits this handler every minute. Its job is to pull pending items from Firestore and create Cloud Tasks for them. The critical design choice is that it enqueues a bounded batch, not everything.
func handleEnqueueNext(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
partition := r.URL.Query().Get("partition")
// Bound the enqueue: only create as many tasks as we can
// dispatch in the next scheduling window.
dispatchRate := 2 // tasks per second
windowSeconds := 60 // cron interval
maxThisCycle := dispatchRate * windowSeconds
iter := fs.Collection("work_queue").
Where("status", "==", "pending").
Where("partition", "==", partition).
OrderBy("priority", firestore.Asc).
OrderBy("created_at", firestore.Asc).
Limit(maxThisCycle).
Documents(ctx)
for {
doc, err := iter.Next()
if err == iterator.Done { break }
if err != nil { http.Error(w, err.Error(), 500); return }
if err := dispatcher.Enqueue(ctx, partition, doc.Ref.ID); err != nil {
log.Printf("enqueue %s: %v", doc.Ref.ID, err)
continue
}
}
w.WriteHeader(200)
}Bounded enqueue is the reason Cloud Tasks never piles up past the dispatch rate times the scheduling window. If you have a million pending items and a 2/s dispatch rate, this handler never enqueues more than 120 tasks per minute. The rest stays in Firestore, queryable and visible, until the next cron tick.
The Enqueue call itself uses named tasks for free idempotency:
func (d *Dispatcher) Enqueue(ctx context.Context, partition, docID string) error {
queuePath := fmt.Sprintf("projects/%s/locations/%s/queues/process-%s",
d.projectID, d.region, partition)
// Named task: creating a task with the same name twice is a no-op.
taskName := fmt.Sprintf("%s/tasks/%s", queuePath, docID)
req := &cloudtaskspb.CreateTaskRequest{
Parent: queuePath,
Task: &cloudtaskspb.Task{
Name: taskName,
MessageType: &cloudtaskspb.Task_HttpRequest{
HttpRequest: &cloudtaskspb.HttpRequest{
HttpMethod: cloudtaskspb.HttpMethod_POST,
Url: d.handlerURL + "?doc_id=" + docID,
OidcToken: &cloudtaskspb.OidcToken{
ServiceAccountEmail: d.invokerSA,
},
},
},
},
}
_, err := d.client.CreateTask(ctx, req)
if isAlreadyExists(err) { return nil } // idempotent
return err
}The payload is only the doc ID. Not the case data, not the URL, not the metadata. The handler re-reads the doc from Firestore. This keeps tasks tiny, keeps schema drift impossible, and keeps Firestore the single source of truth for what the work actually is.
The /process-one Handler
The worker is where idempotency lives. Cloud Tasks will retry. A handler that corrupts state on retry will corrupt state in production. Structure it as read-claim-work-outcome:
func handleProcessOne(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
docID := r.URL.Query().Get("doc_id")
doc, err := fs.Collection("work_queue").Doc(docID).Get(ctx)
if err != nil {
http.Error(w, err.Error(), 500)
return
}
data := doc.Data()
// 1. Idempotency check: if already terminal, ack without re-processing.
switch data["status"] {
case "done", "failed":
w.WriteHeader(200)
return
}
// 2. Claim
_, _ = doc.Ref.Update(ctx, []firestore.Update{
{Path: "status", Value: "processing"},
{Path: "updated_at", Value: time.Now().UTC()},
})
// 3. Do the work
result, workErr := doActualWork(ctx, data)
// 4. Record outcome
switch {
case workErr == nil:
_, _ = doc.Ref.Update(ctx, []firestore.Update{
{Path: "status", Value: "done"},
{Path: "result", Value: result},
{Path: "completed_at", Value: time.Now().UTC()},
})
w.WriteHeader(200)
case isRetriable(workErr):
_, _ = doc.Ref.Update(ctx, []firestore.Update{
{Path: "status", Value: "pending"},
{Path: "attempts", Value: firestore.Increment(1)},
{Path: "last_error", Value: workErr.Error()},
{Path: "updated_at", Value: time.Now().UTC()},
})
http.Error(w, workErr.Error(), 500) // Cloud Tasks retries
default:
_, _ = doc.Ref.Update(ctx, []firestore.Update{
{Path: "status", Value: "failed"},
{Path: "last_error", Value: workErr.Error()},
{Path: "updated_at", Value: time.Now().UTC()},
})
w.WriteHeader(200) // Do NOT retry permanent failures
}
}Three rules buried in those lines are worth pulling out. Cloud Tasks treats any 2xx as success and any 5xx as retriable. A permanent failure, the kind a retry cannot fix, must return 200 even though it is a failure. Otherwise you loop forever. Conversely, a transient network hiccup must return 500 so Cloud Tasks backs off and tries again. The isRetriable function is where you encode what your domain considers transient: context timeouts, 429s, temporary upstream unavailability. Everything else is permanent and gets marked failed.
Four Knobs That Must Agree
This is where this pattern most often gets misimplemented. Rate control is not a single number. It is four numbers, two on Cloud Tasks and two on Cloud Run, and they must be coherent.
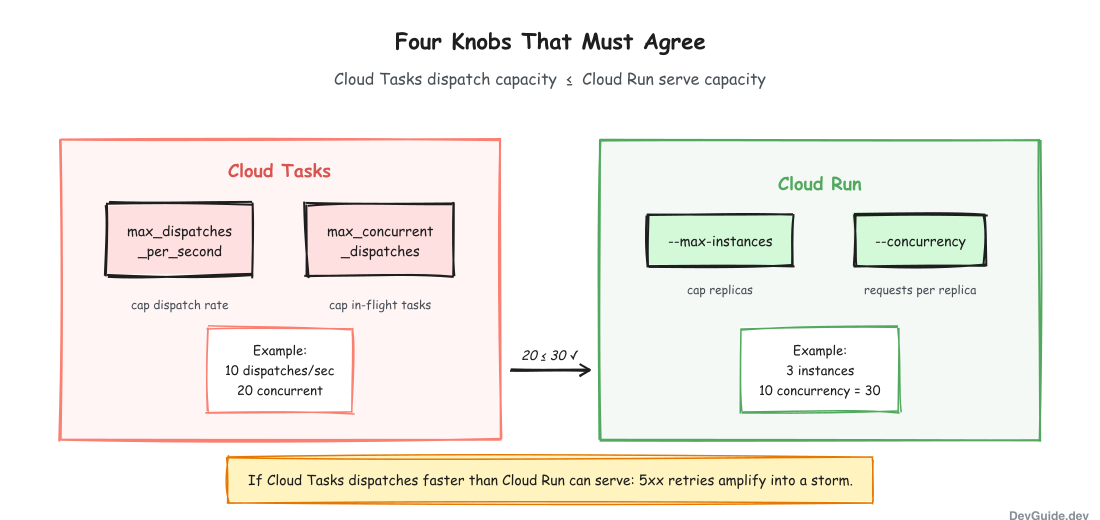
| Layer | Knob | Purpose |
|---|---|---|
| Cloud Tasks | max_dispatches_per_second | Cap dispatch rate regardless of queue depth |
| Cloud Tasks | max_concurrent_dispatches | Cap in-flight dispatched tasks at any moment |
| Cloud Run | --max-instances | Cap how many container replicas can exist |
| Cloud Run | --concurrency | Concurrent requests per replica |
The failure mode to internalize: if Cloud Tasks dispatches at 50 requests per second but Cloud Run caps out at 1 instance with concurrency 10, your real throughput is 10 per second. The other 40 per second get a 503, Cloud Tasks treats the 503 as retriable, and now you have a retry storm adding load to an already saturated handler. The more you push, the worse it gets.
The rule is simple: Cloud Tasks dispatch capacity must be less than or equal to Cloud Run serve capacity. If you want to go faster, raise Cloud Run first, then raise Cloud Tasks. If you want to slow down, lower Cloud Tasks first, then scale Cloud Run down.
Safe starting points for three common shapes:
# Memory-hungry worker (scraper, browser automation)
setup-heavy:
gcloud tasks queues create process-heavy \
--max-dispatches-per-second=2 \
--max-concurrent-dispatches=5 \
--max-attempts=3 \
--min-backoff=30s \
--max-backoff=1h
gcloud run services update worker \
--max-instances=1 --concurrency=1
# Medium CPU worker (parse + transform)
setup-standard:
gcloud tasks queues create process-standard \
--max-dispatches-per-second=10 \
--max-concurrent-dispatches=20
gcloud run services update worker \
--max-instances=3 --concurrency=10
# Trivial I/O handler (enrich with one API call)
setup-light:
gcloud tasks queues create process-light \
--max-dispatches-per-second=50 \
--max-concurrent-dispatches=100
gcloud run services update worker \
--max-instances=10 --concurrency=80Pick one, watch it for a week, then adjust based on the real error rate and queue depth.
Guardrails That Keep You Off the Pager
The pattern is only as good as the alerts you wire around it. Five things every production deployment needs.
Queue depth alert. A Cloud Monitoring alert when cloud_tasks.queue_depth for any queue exceeds a threshold. For most pipelines, 1,000 is a reasonable number. The alert does not mean something is broken. It means the dispatcher is falling behind or a downstream is stuck.
Oldest task age alert. If the oldest task in the queue is older than your longest normal dispatch cycle, dispatch itself has stalled. 24 hours is a generous threshold; shorter is better for fast-moving pipelines.
Enqueue ceiling in the dispatcher. This lives in the /enqueue-next handler, not in monitoring. The handler computes max = dispatch_rate * window_seconds and caps the Firestore query limit at that. Without this, a scheduler hiccup followed by a catch-up run dumps a day of pending work into the queue in a single cron firing. Bounded enqueue keeps the queue depth bounded by the dispatch rate, not by how much work exists.
Dead letter queue. After max_attempts retries, tasks must go somewhere you can see. Configure a DLQ policy on the Cloud Tasks queue, then a daily Cloud Scheduler job that drains the DLQ, marks the corresponding Firestore docs as permanently failed, and alerts if the DLQ is non-empty. Without this, failed tasks just vanish and the Firestore doc stays stuck at status=processing forever.
Circuit breaker. If downstream error rate crosses 20% over 5 minutes, pause the queue:
gcloud tasks queues pause process-heavyPaused queues keep their tasks but stop dispatching. You fix the root cause, then resume. This is a better failure mode than “retry 10,000 tasks into a broken downstream for three hours.”
Anti-Patterns to Check For
Five mistakes show up repeatedly in code review. Grep your own pipelines for each.
Cloud Tasks as durable store. If your producer writes to Cloud Tasks and nowhere else, you have no source of truth. You cannot query “how much work is pending” at a business level. You cannot replay. You lose items past 30 days. Move the producer to Firestore first.
Missing named tasks. A task created without task.name = deterministic_id is a duplicate waiting to happen. If /enqueue-next runs twice for overlapping batches, you get duplicate processing. Named tasks are free. Always use them.
Big task payloads. A task payload over a few hundred bytes is a schema migration landmine. Pass the doc ID and re-read from Firestore. Your payload never needs to change because it is always just an ID.
The --concurrency=1 trap. A handler that takes 30 seconds with --concurrency=1 --max-instances=1 caps at 2 tasks per minute. A Cloud Tasks queue dispatching at 50 per second produces a three-hour backlog in one scheduling cycle. Four knobs must agree.
Ignoring the DLQ. A DLQ you do not drain is a graveyard you forget about. Every DLQ needs a daily drain job that marks the Firestore doc, alerts, and moves on.
Migrating from In-Process Goroutines
If you already have the goroutine architecture, do not big-bang. A gradual rollout in five phases is the safe path.
Phase 1: infrastructure (1-2 days). Create Cloud Tasks queues via Makefile targets. Deploy /enqueue-next and /process-one handlers alongside existing goroutine code. They do not receive traffic yet.
Phase 2: feature flag (1 day). A USE_CLOUD_TASKS=true environment variable controls whether producers enqueue to Cloud Tasks or kick off goroutines. Default false. Set per partition or per work type.
Phase 3: canary one work type (3-5 days). Flip the flag for the smallest, safest partition. Watch the Cloud Tasks dashboard, Cloud Run logs, Firestore queue state, and admin dashboard metrics.
Phase 4: graduated rollout (1 week). 10% to 50% to 100% of that work type. Then the next work type. Keep the goroutine code path as a fallback.
Phase 5: remove old path (1 day). After two weeks stable on 100%, delete goroutine code. Remove the feature flag. The new system is the only system.
In the pipeline where I rolled this out, the Firestore work-queue collection was already the source of truth; Cloud Tasks was added on top without any schema change. That matters: the migration is additive, not disruptive. You keep your existing producer writes, you keep your existing admin queries, and you layer rate control on top.
Your Checklist
If you run a Cloud Run pipeline today, here are the things to verify this week.
- No business logic lives in a
go func() { for { ... } }()that outlives a single request. - Producers write to Firestore (or a real database). Cloud Tasks is only a transport.
- Every Cloud Tasks task has
task.nameset deterministically from the work item ID. - Task payloads are IDs, not data. Handlers re-read from Firestore.
-
/process-onechecksstatusat the top and returns 200 for terminal states. -
isRetriableis explicit. 500 for retriable, 200 for permanent. Never the other way. -
max_dispatches_per_secondtimes handler latency is less thanmax-instances * concurrency. - Queue depth alert wired to Slack or Telegram.
- Oldest task age alert with a 24-hour threshold.
- DLQ configured with
max_delivery_attempts, drained daily. -
/enqueue-nextcaps its Firestore query atdispatch_rate * window_seconds. - A runbook for pausing and resuming the queue (
gcloud tasks queues pause NAME).
Why This Works
Firestore gives you durability, rich queries, admin visibility, and a schema that is easy to extend. Cloud Tasks gives you rate control, backpressure, retries with exponential backoff, and dispatch-level observability. Neither of them does the other’s job well. Together they cover both.
The goroutine pattern looks like it is doing one thing (background work) when it is actually doing three (storage, scheduling, execution) all in RAM. Splitting those three responsibilities across Firestore and Cloud Tasks is what makes the system durable.
The discovery worker that went silent for 30 hours did not need a stronger goroutine. It needed to not have one. The pointer it was advancing belonged in Firestore. The rate at which it advanced belonged in Cloud Tasks. The code that did the actual advancing belonged in a 200-line HTTP handler that could die at any moment without losing a single record.
Cloud Run lets containers die. Design for it. Put state where it can survive.