Teaching AI to Distrust Itself: How I Built a 98% Accurate OCR Model by Learning to Question Everything
Building an OCR model taught me that the hardest part of machine learning isn't the model - it's the labels. Here's how iterative outlier detection and healthy skepticism got us to 98% accuracy.

The model was 90% accurate. We had 2,000 labeled images. The architecture was sound - a CRNN with CNN feature extraction, bidirectional LSTM for sequence modeling, and CTC loss for variable-length output. Everything looked right.
But 90% accuracy on OCR means 1 in 10 fails. In production, that’s not a minor inconvenience - it’s a broken system.
I stared at the confusion matrix and asked the obvious question: “Is the model wrong, or are the labels wrong?”
The Dirty Secret of Machine Learning
Everyone talks about model architecture, hyperparameter tuning, and data augmentation. Nobody talks about the hours spent staring at mislabeled training data, wondering if that character is a lowercase ‘l’, uppercase ‘I’, or the number ‘1’.
Our initial labels came from an OCR suggestion system. It was supposed to save time. Instead, it poisoned our dataset with a 27% error rate - more than a quarter of our “ground truth” was fiction.
Here’s what the conventional wisdom says: “Get more data.” Here’s what actually works: “Fix the data you have.”
The Verification Trap
My first instinct was automation. Modern vision models can read text in images, right? Let’s use Claude’s vision capability to verify each image.
I spun up parallel agents - 5 of them - each processing batches of images simultaneously. Efficiency! Scale! The future of data labeling!
The correction rate? 2%.
That’s not a typo. With a basic verification prompt, parallel agents caught only 2% of the errors. With a stricter prompt emphasizing careful character-by-character analysis, they caught 10%.
Meanwhile, when I processed images sequentially - one at a time, in the main conversation - the correction rate jumped to 65%.
What happened?
Parallel agents rubber-stamp. Without conversational context, without the pressure of a human watching their work, without the natural rhythm of doubt and verification that comes from sequential processing, the agents defaulted to approval. “Looks right to me. Next.”
This isn’t a bug in the AI. It’s a mirror of human behavior. Ever reviewed 50 pull requests in a row? How careful were you on number 47?
The Outlier Detection Loop
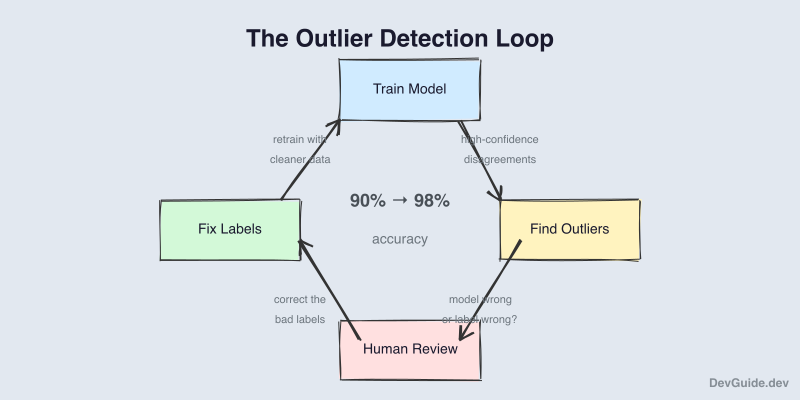
After manual verification (sequential, painful, necessary), we trained the model. It reached 90%. Good, but not good enough.
Then I asked a different question: “What if the model already knows which labels are wrong?”
The insight is counterintuitive: a 90% accurate model, by definition, disagrees with 10% of the labels. Some of that 10% are model errors. But some of that 10% are label errors.
If we train a model, run inference on the training data, and compare predictions to labels - we get a list of “disagreements.” That list contains both:
- Model mistakes (correct label, wrong prediction)
- Label mistakes (wrong label, correct prediction)
The trick is telling them apart. Here’s the approach:
def find_outliers(model, dataset, labels, confidence_threshold=0.7):
"""Find samples where model prediction differs from label."""
outliers = []
for filename, label in labels.items():
image = load_image(filename)
prediction, confidence = model.predict_with_confidence(image)
if prediction != label and confidence > confidence_threshold:
outliers.append({
'filename': filename,
'label': label,
'prediction': prediction,
'confidence': confidence
})
return sorted(outliers, key=lambda x: -x['confidence'])The key is the confidence threshold. High-confidence disagreements are more likely to be label errors - the model is “sure” the label is wrong. Low-confidence disagreements are more likely model errors - the model is uncertain and probably just guessed wrong.
The Results: Two Rounds of Refinement
Round 1:
- Model accuracy: 90%
- Outliers found: 253 (12.6% of dataset)
- After human review: 139 corrections (54.9% of outliers were bad labels)
After correcting those 139 labels and retraining:
Round 2:
- Model accuracy: 98.5%
- Outliers found: 26 (1.3% of dataset)
- After human review: 19 corrections (73.1% of outliers were bad labels)
Notice the pattern. As the model improved, the outlier-to-correction ratio increased. In round 1, about half the outliers were label errors. In round 2, nearly three-quarters were. The better the model gets, the more trustworthy its disagreements become.
Also notice: we removed 2 images entirely. Some OCR images had characters clipped at the edge, making the “correct” label ambiguous. When you can’t determine ground truth, the only honest answer is to remove the sample.
Final result: 98% accuracy on 1,998 images.
The Uncomfortable Truth About Scale
This approach doesn’t scale. That’s the point.
We manually reviewed 279 potential errors across two rounds. We didn’t automate the final decision - a human looked at each outlier and decided whether the model or the label was correct.
But here’s the thing: we got 98% accuracy from 2,000 images. Not 20,000. Not 200,000. Two thousand carefully curated samples beat the hypothetical dataset ten times larger with 27% label noise.
In machine learning, there’s a seductive lie: “More data will fix it.” Sometimes it will. But dirty data at scale is just dirty data with higher GPU bills.
The Architecture That Made It Work
For completeness, here’s what the model looks like:
CRNN Architecture:
├── CNN Feature Extractor (ResNet-style blocks)
│ ├── 64 → 128 → 256 channels
│ └── Spatial reduction for sequence input
├── Bidirectional LSTM (2 layers, 256 hidden)
│ └── Captures left-right character context
└── CTC Loss
└── Handles variable-length sequences7.6 million parameters. Nothing exotic. The innovation wasn’t in the model - it was in systematically fixing what we fed it.
Lessons for Your Next ML Project
1. Your labels are probably wrong. Not all of them. But enough to cap your accuracy at a ceiling you won’t break without addressing them. Budget time for label quality, not just label quantity.
2. Sequential verification beats parallel verification. This applies to humans too. The reviewer who processes files one at a time, with context and continuity, catches more errors than the team of reviewers each taking a random slice.
3. Use your model to debug your labels. Once you have any trained model - even a mediocre one - it becomes a tool for finding its own training data problems. High-confidence disagreements deserve human attention.
4. The iteration loop matters more than the starting point. Train → Find outliers → Fix labels → Retrain. Each cycle improves both the model and the data. The compounding effect is powerful.
5. Know when to remove data. Ambiguous samples hurt more than they help. If two humans would disagree on the correct label, the model shouldn’t be penalized for getting it “wrong.”
The Meta-Lesson: Distrust Enables Trust
The path to 98% accuracy wasn’t believing in the model or the labels. It was systematically questioning both.
Every outlier review session was an exercise in asking: “Is the model wrong, or am I?” Sometimes the model caught character confusions I had missed. Sometimes I caught patterns the model hadn’t learned yet. The dialogue - not blind trust in either - is what improved the system.
This is, perhaps, the core skill of applied machine learning. Not architecture design. Not hyperparameter tuning. Just the willingness to look at your data, notice the disagreements, and investigate them one by one.
The model was 90% accurate. Then it told me which labels to doubt. And doubt, carefully applied, got us to 98%.
The project used PyTorch with Apple Silicon MPS acceleration, a Flask-based labeling tool for human review, and more patience than I initially budgeted for.